Thoughts on HTTP instrumentation with OpenTelemetry

It’s the summary of what I learned writing high-scale REST services, instrumenting native HTTP Client in .NET, along with some research I’ve done on other HTTP clients and languages. I’m not an HTTP expert though and if you are please come and help us work on OpenTelemetry HTTP conventions!
Instrumentation requirements
HTTP instrumentation is probably covered by all distributed tracing solutions and still, while we agree on attributes we want to capture, there is a lot of ambiguity about edge cases: retries, redirects, or lower-level details.
Let’s start by listing what I think instrumentation should achieve
- Answer typical user questions about the request: when it was made, in which context, how long it took, what were destination and result.
- Enable instrumentation (ideally without code) at runtime. Code configuration should be also possible and some languages would prefer an explicit way. For Java, Python, Node.js, and .NET enabling HTTP tracing implicitly is a standard for users.
- Support generic use-case consistently (within laws of physics) between client implementations, languages, configuration, and usage
- Don’t be expensive: there should be nearly zero perf impact when there is no OpenTelemetry SDK (for native instrumentation), the default configuration should have a small perf impact. Extra details cost more for users in terms of telemetry bills and performance and should be opt-in.
- Don’t break HTTP client core functionality: instrumentation should follow OpenTelemetry error conventions: they are visible, but applications should keep working no matter what happens with tracing. Tracing API stability is a big part of it.
High-level overview
There is more context and reasoning later, here are just a few main points.
TL;DR:
- each try or redirect is an HTTP span, it has a unique context that must be propagated downstream - HTTP clients don’t control how their APIs are used and spans created need to have the same meaning regardless of use-case. Unambiguously mapping client spans to service span also requires each try/redirect to have/propagate individual context.
- nesting retries under another span is not always feasible because HTTP client APIs can be used in different ways and the client doesn't know about all retries. While higher-level spans with nested retries may be desirable, for the most popular happy use case, they are redundant. Users or libraries that do HTTP calls MAY add more instrumentation layers when it makes sense.
- DNS, TLS, TCP, and any lower levels can be instrumented, but should not be enabled by default (due to low demand, costs, and perf implications). They can be added incrementally as events, logs, or new nested span (with other than HTTP semantics). We need some real-world instrumentation examples to come up with conventions.
- current attributes have proven themselves over years and are great!
More details
So here are more details on why I came up with this approach.
First, let's think about HTTP client API:
- it has
sendcall to execute a request - it likely has handlers/interceptors for auth, retries, logging, etc, and probably users use them for retries, but not all of the users and not all the time
- it has the configuration (default retry policy, auto-redirects, response buffering, etc).
Candidates for instrumentation is this high-level send call or lower-level physical RPC calls. Configuration affects high-level send behavior.
Below I’m arguing that app-specific variations in send behavior make is a bad candidate for instrumentation and we should instead instrument low-level RPC calls (tries and redirects).
HTTP Client use-cases
Let’s talk about some use-cases to understand what’s generic and not app-specific.
Basic, happy case
OkHttpClient client = new OkHttpClient();Request request = new Request.Builder()
.url(url)
.build();try (Response response = client.newCall(request).execute()) {
return response.body().string();
}
Source: https://square.github.io/okhttp/
Sync or async HTTP request, no auth, no redirects, retries, the body is buffered before HTTP client API call completes. This case is rarely how we write code in production, but we should optimize perf/user costs for this as much as we can since it’s an absolute majority of HTTP requests.
Retries
Perhaps handlers and interceptors are the most common idiomatic way to do retries (e.g. HttpClient handlers in .NET or okhttp interceptors).
OkHttpClient client = new OkHttpClient();
client.interceptors().add(new Interceptor() {
@Override
public Response intercept(Chain chain) throws IOException {
Request request = chain.request();
Response response = chain.proceed(request);
int tryCount = 0;
while (!response.isSuccessful() && tryCount < 3) {
tryCount++;
// you'd also need backoff and jitter
response = chain.proceed(request);
}
return response;
}
});Source: https://stackoverflow.com/questions/24562716/how-to-retry-http-requests-with-okhttp-retrofit
But sometimes you’d use Project Reactor retries or RxJava ones. Sometimes you want something fancy (e.g. pluggable HTTP client implementation like us in Azure SDK) and you’d handle retries on the level higher than HTTP client.
There are no rules and no control/knowledge on HTTP client level of how retries are handled by application. The only consistent approach is to create a span per try.
Let’s say we don’t create a span per try and only instrument an HTTP client send call (with perhaps some events on each try, so we are not completely blind). Then, depending on usage, we’d sometimes have span per try (when app handles retries above HTTP client API) and sometimes span per send call. This is inconsistent and requires some explanation to users. Users are also not able to tell which server span is caused by which client try.
Can we still instrument HTTP client high-level calls?
I believe knowing the number of retries and overall call duration and result is extremely useful. But can we do it? Sometimes we can but HTTP client doesn’t know about it and we’ll end up misleading users by telling them they didn’t have retries when in reality they did but handle them on the higher level.
So my answer is no: auto/native instrumentation can’t do better than single try instrumentation.
We can ask users to do higher-level spans with manual instrumentation. We can also do it in some controlled environments (e.g. HttpClientFactory with retry policy in .NET) or libraries that wrap HTTP calls. Still, I have concerns about the happy case (~99% of requests are not retriable). Adding extra span on HTTP client API surface by default increases costs to users, it is also redundant — doesn’t give any extra context to users.
User experience:
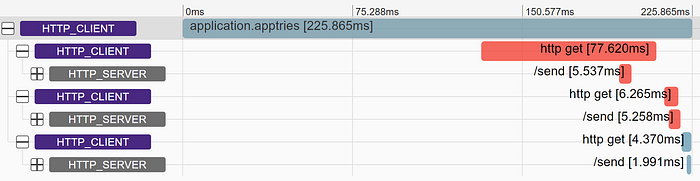
- It’ clear which server span belongs to which client span.
- It’s clear when each retry starts, ends, if the backoff interval is good and HTTP status of each try (which potentially can be achieved with events too)
- User is responsible for wrapper span creation and can put stream reading and logging under it

- It’s impossible to tell which server span belongs to which client span (timestamps are misleading)
- It may be clear when each retry starts, ends, backoff interval and HTTP status of each try if it’s done with events, but needs backend support.
- Users must know how it works and should use interceptors/handlers for tracing to work properly or they will see a mixture of these two pictures (maybe even in the same app)
Here’s the code for this example using okhttp and instrumentation agent, just different usage patterns.
If I didn’t convince you yet, here is another reason to have a unique span and span context per try:
- user investigates the reason for retries
- they ask for support from the downstream service owner e.g. cloud provider.
- with a span context common among multiple tries, their ask is ambiguous (check what happened with something that has certain
traceparent). Since we don’t even know if this particular try ever reached the cloud provider, getting support for this request would likely be hard. It increases costs for both: users and service providers.
Having a unique client span per physical HTTP request is essential to get support from downstream services and investigate issues.
Redirects
Redirects can be handled by user app or by HTTP client (this is the configuration HTTP client usually knows about).
Redirects are different HTTP requests with different durations, end results, and URLs. Users may be interested in knowing which service returned the error or if the wrong redirect location was returned, or if the request took too long — it may help them dig into the right downstream service for the root cause. Or maybe their auth is not working correctly (and auth headers change between redirects). Arguably, span per redirect makes total sense. Also, since users sometimes opt out of auto-redirect, we’ll end up creating a per-redirect HTTP span for them anyway at least sometimes.
So for the sake of consistency and to give users better observability, I believe each redirect should be a separate HTTP span.
Async body stream reading/writing
What if the response body is big and the user configured the client not to buffer the body before HTTP Client API call ends? There is no way of knowing when the user will read the body, i.e. we can’t measure time-to-last-byte. We also don’t know if reading stream results in an error and needs to be retried.
We can eventually instrument network streams to help with it (beyond the HTTP instrumentation layer). but for now, tracing it remains in the scope of manual instrumentation (or some client library instrumentation that does this call).
Long polling and streaming
This is uncharted territory. With gRPC streaming, I believe, the state of art is to instrument a request/response, but not instrument a single message. Since the stream may have an app’s lifetime and be reused to send independent messages, it makes sense to instrument each message separately. Unfortunately, this is fully custom since there is no metadata propagation on the message or standard way to handle messages. Manual instrumentation is the best we can do. Still, HTTP semantics doesn’t really apply to those micro-calls (they don’t have HTTP methods, URL, or status codes).
Other instrumentation concerns
Context Propagation
Instrumentations should propagate context for each try — it allows unambiguously connect client and server spans and helps users understand their systems better.
Context propagation standard actually depends on destination, but runtime or native-instrumentations can’t usually deal with it and have to have one propagator for all requests in the process.
Manual implementations and client libraries that instrument HTTP calls should apply their best knowledge about downstream service and use context propagation format that it supports. I believe they should additionally propagate W3C Trace-Context to be future-proof.
Since HTTP request instances can be reused (between redirects or retries) and there could be potentially multiple layers of instrumentation, instrumentation can’t assume that there is no context on the request. If requests can be resued, instrumentation MUST clean context before injecting a new one.
Sampled-out spans still have unique context that MUST be injected. But if context is invalid (instrumentation is off), context MUST NOT be injected.
Sampling
Sampling decisions are beyond instrumentation control, it should provide attributes that are available before span is started and let sampler decide. Conventions should list attributes that are needed for sampling.
Providing attributes to sample before making decision increases no-op costs which may be a blocker for native instrumentation. Instrumentation SHOULD be able to determine if there is no OpenTelemetry SDK in the app. Ideally, we’d want an extremely efficient method on Tracer/TracerProvider to help with that. The result must not be cached by the instrumentation (in case of dynamic runtime enablement for tracing).
Status
HTTP client can’t be opinionated: it doesn’t know if 404 is an error, but probably knows that 200 is a success and 500 is a failure. There should be a mapping between HTTP status code and span status. There could be a number of ways to deal with statuses like 404 that don’t imply success or failure:
- users can override them in SpanProcessors
- client libraries that make HTTP calls usually know a bit more about particular status codes and can make better success/failure decision
- an extra manual span that wraps HTTP call with retries may also set overall status (making explicit that operation underneath was eventually successful)
- Vendors may and do provide additional tricks to help ignore certain errors
Still, neither of these solutions is perfect. Based on my experience, there are a lot of complaints and asks to get better at categorizing errors and some way for users to set expectations to instrumentation would be beneficial.
Request/response body
Some customers want to include request/response body on the spans. This has a number of potential security, privacy and performance issues and I believe standard instrumentation cannot afford it. We should provide an example of how to add them manually through logs or events.
Lower levels
There are many other interesting things below HTTP that can go wrong: and need observability: DNS, TLS, TCP. Here are some thoughts on this :
- I didn’t hear about the need to instrument lower levels from customers (so this is my availability bias)
- We don’t have a lot of examples of such instrumentations (Wireshark doesn’t count)
- We should be cautious about performance and amount of telemetry (since it seems most customers don’t need it)
- We may express them as logs/events (with verbosity) that customers opt-in to.
- They can be added incrementally and don’t have to block HTTP spans semantics progress as long as there is a consensus on the direction
Higher Levels
With bare-minimum instrumentation, HTTP CLIENT spans are children of SERVER spans (in the same process). But there can be more layers than that.
Client libraries that work over HTTP have a lot of context that auto-instrumentation doesn’t have:
- they can create extra span for nested retries/redirect
- they can measure time for response body stream reading
- they frequently know the real status of HTTP spans and the result of the overall logical operation
- they know extra details about underlying services that are important to users
- they also know context propagation protocols supported by downstream service
If e.g. a database client works over HTTP, it may create HTTP spans for the transport layer, but should also create DB spans. There could be multiple nested HTTP spans under each DB call because of complex operations or retries.
Same with manual instrumentation: users have way more context than HTTP clients, they can create their own (non-HTTP) spans to help with nested retries and redirects, the logical result of an operation, including response stream reading under that span, write event/log with request/response body or anything else they may be interested in.
Instrumentation pseudo code
// reduces attribute collection perf impact
// if there is no OTel SDK
instrumentationEnabled = tracer.isEnabled()if (instrumentationEnabled) {
samplingAttributes = getSamplingAttributes()
span = tracer.startSpan(
spanName,
parentContext,
SpanKind.CLIENT,
samplingAttributes) // next layers of instrumentation can discover this span
scope = span.makeCurrent()
if (span.isRecorded()) {
// add other non-sampling-related attributes
span.addAttribute(...)
}
if (span.getContext().isValid()) {
// may internally take care of cleaning up
// context before injection
propagator.inject(span.getContext(), setter)
}
}try {
response = await send(request)
if (instrumentationEnabled && span.isRecorded()) {
span.setAttributes(STATUS_CODE, response.statusCode)
span.setStatus(httpCodeToStatus(response.statusCode))
}
} catch (Exception ex) {
if (instrumentationEnabled && span.isRecorded()) {
span.setException(ex);
}throw ex
} finally {
if (instrumentationEnabled) {
scope.close()
span.end()
}
}
